졸업프로젝트로 실시간 객체인식을 통한 자동 결제 서비스를 만드는 중이다. 학교 매점 특성상 특정 시간대에만 사람들이 몰리는데, 그에 비하여 매점 크기가 너무 작아 계산대를 늘리기 힘든 구조다. 특정 상품들의 경우 생협 계산대에 계신 분들이 직접 바코드북에서 바코드를 찾아 찍어야 하다보니 일반 계산대보다 오래걸린다는 점을 해결하기 위해 이 서비스를 만들게 되었다.
그 중 내가 맡은 파트는 인공지능 파트다. 상품 데이터 어노테이션과 학습 - 이렇게 두 가지 부분으로 나눠서 글을 쓰고자 한다.
서버 세팅은 앞서 다른 글에 작성해뒀다. 2023.05.16 - [학교 공부/졸업 프로젝트] - [Ubuntu20.04] Yolov5를 위한 우분투 세팅
(우분투 세팅 글은 두번째 학기에 서버를 받았을 때 쓴 글이나, 현재는 서버 한도초과로 셧다운되어 방학 때 쓰던 실물컴퓨터를 사용중이다.)
1. Roboflow를 이용한 이미지 어노테이션
처음에는 국내 사이트인 블랙올리브(https://cloud.blackolive.ai/)를 사용하여 라벨링을 했다. 하지만 해당 서비스에서는 yolo형식에 맞춘 데이터셋 생성이 불가능하고, yolo형식에 맞춰 조정하는 과정이 너무 복잡하여 하는 수 없이 roboflow(https://roboflow.com/)를 이용해 다시 라벨링을 했다.
프로젝트 생성
로그인/회원가입을 한 뒤, 새로운 프로젝트를 만들어준다. 참고로 무료 계정으로는 public 프로젝트만 만들 수 있다. 이렇게 만드는 경우 universe page(https://universe.roboflow.com/)에 데이터셋이 공개되며, 다른 사람들이 다운받을 수 있다. (반대로 다른 사람들의 데이터를 다운받을 수도 있다.)

yolov5에서는 바운딩 박스를 이용하니 Object Detection(Bounding Box)를 선택한다. 그리고 그 뒤 항목들은 프로젝트에 맞게 작성한다.
Upload
영상/이미지들을 업로드해준다. 아이폰으로 촬영한 영상의 경우 형식에 맞지 않는다는 경고문이 뜨기도 하는데, 이 경우 유튜브에 일부공개로 영상을 업로드한 뒤, Import YouTube Video를 해주면 된다. (유튜브스튜디오에 들어가면 본인이 올린 영상들을 관리할 수 있다.)
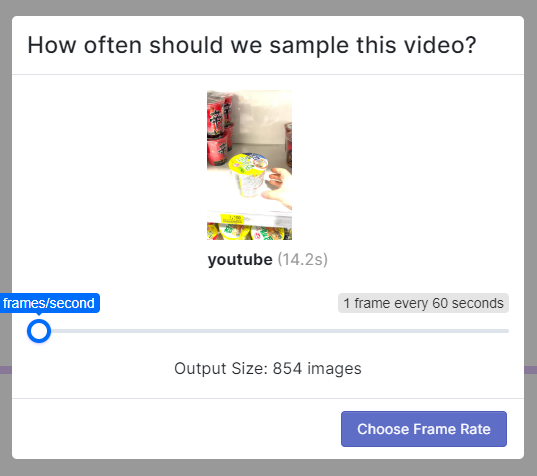
frame per sec를 이용해 이미지 수를 조정하자. roboflow 무료계정에서는 최대 10000개의 source image 사용이 가능하니, 이 점을 참고하여 정하면 되겠다.
Assign
말 그대로 어노테이션할 이미지를 할당해준다. 팀원을 프로젝트에 초대해서 분배할 수도 있고, 외주를 맡길 수도 있다.
이 때, annotation 규칙을 설정할 수도 있다. 클래스명 표기법 등을 써두면 좋을 것 같다. 우리 팀의 경우 노션과 디스코드를 이용해서 여기에 규칙을 작성하지는 않았다.
Annotate

Unassigned는 labeler가 할당되지 않은 이미지들을 나타낸다. 지금은 모든 이미지가 할당되어서 비어있다.
Annotating에서는 각 업로드되어 할당된 batch마다 labeler, 이미지 수, annotation 진행도를 확인할 수 있다. 각 batch의 오른쪽 하단 Start Annotating을 누르면 바로 annotation으로 넘어간다. 이 때, 다른 사람이 할당받은 batch도 annotation이 가능하다.
batch를 그냥 클릭하면 세부 내용을 확인가능하다.
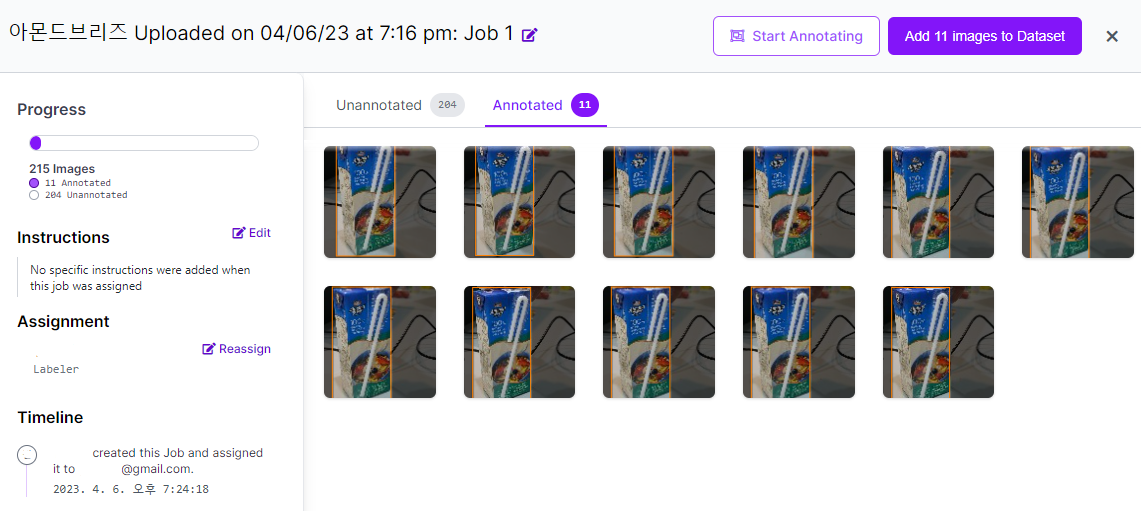
Annotation을 한 이미지는 Annotated에 표시된다. Add images to Dataset을 이용해 바로 데이터셋으로 넘겨줄 수 있으며, 이 때 train, test, validation set의 비율을 정할 수 있다.
작은 팁을 주자면, R을 누르면 이전 bounding box를 그대로 가져오고, D를 누르면 박스 수정으로 모드가 바뀐다. R, D와 화살표 키를 잘 이용하면 영상을 업로드해서 Annotation하는 경우 시간을 조금이나마 단축시킬 수 있다. 집중하면 1분에 5개 정도는 할 수 있다... 부디 개수 조정을 잘 하길 바란다. 우리 팀의 경우 4600개의 이미지를 2달에 걸쳐 라벨링했고, 지도교수님과 멘토님 모두가 당황하셨다...
Dataset
Dataset에서는 지금까지 라벨링한 데이터를 train, test, valid와 클래스, tag에 따라 필터링해 볼 수 있다.
Generate
Generate 탭에서는 이미지 preprocessing과 augmentation을 적용해 최종 데이터셋을 생성할 수 있다.
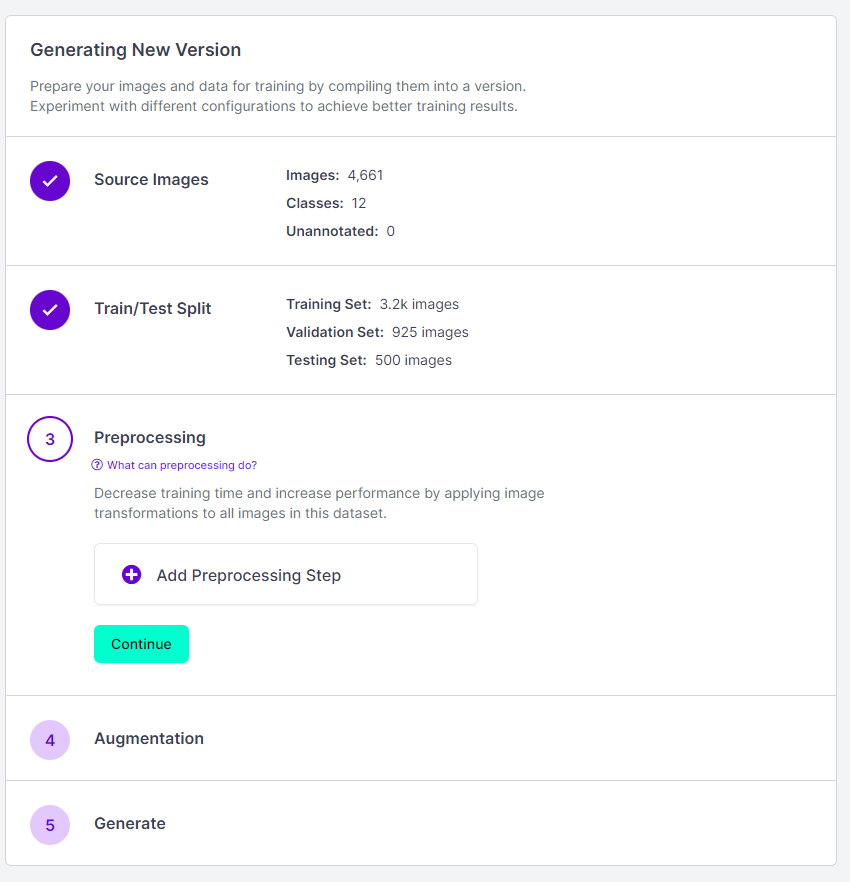
Proprocessing에서는 원하는 대로 Auto-orient, Static Crop, Resize 등을 할 수 있다. Resize는 거의 필수고, Modify classes를 통해 클래스명을 변경하거나 제외하고 데이터셋을 생성할 수 있다.나머지 preprocessing은 본인 데이터셋/프로젝트에 맞춰 설정하면 되겠다.
Augmentation은 말 그대로 augmentation이다. 다양한 augmentation 기법을 적용 가능하다. 본인 데이터셋/프로젝트 특성을 잘 파악해서 적절하게 적용하는 게 필요하다.
이제 Generate를 해준다. 무료 요금제에서는 최대 50000개의 이미지까지 생성이 가능하다. 생성된 데이터셋은 Versions에 서 확인가능하다.
Versions
Custom Train에서 YOLOv5 형식을 선택해 Get Snippet을 한다. 이렇게 데이터셋은 완성되었다.
2. YOLOv5 학습
다운받은 데이터로 학습을 시켜주자. 나는 외부 데이터셋과 roboflow 데이터셋을 합쳐서, 약간의 수정을 해줬다.
기본적인 리눅스(ubuntu) 명령어는 안다고 가정하고 작성하겠다.
yolov5 설치
https://github.com/ultralytics/yolov5#documentation 공식 깃허브의 Documentation을 따라하면 된다.
이하는 https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/ 를 참조하여 진행했다.
미리 comet과 같은 logging & visualization 툴을 설정해두면 좋다. (https://docs.ultralytics.com/yolov5/tutorials/train_custom_data/#comet-logging-and-visualization-new)
파일 경로 수정
roboflow에서 생성한 데이터는 다음과 같은 경로가 되어야 한다. images 폴더에는 이미지 파일이, labels 폴더에는 txt 파일이 들어가야 한다.
yolov5
└─data
├─test
│ ├─images
│ └─labels
├─train
│ ├─images
│ └─labels
├─valid
│ ├─images
│ └─labels
└─data.yaml`data.yaml`의 파일명은 변경해도 된다. (학습 명령어에서 변경한 파일명을 써주면 된다.)
`data.yaml`의 내용에서 경로를 조금 수정해주자.
#yolov5/data로 이동
vim data.yamltrain: ./data/train/images
test: ./data/test/images
val: ./data/valid/images
#이하 내용은 데이터셋에 맞게 변경 혹은 유지훈련
#yolov5로 이동
python train.py --img 640 --epochs 100 --batch-size 16 --data data.yaml --weights yolov5s.pt --name run_230515_2051- --img는 데이터셋 이미지 크기에 맞추면 된다
- --epochs는 반복 횟수를 설정하면 된다.
- --batch-size로 batch 크기를 조정가능하다. GPU메모리 초과가 뜨면 batch 크기를 줄여주자.
- --data 에는 훈련에 쓰이는 yaml파일명을 그대로 작성하면 된다.
- --weights는 베이스가 될 pt파일을 작성한다.
- --names는 저장될 이름을 설정한다.
- --device로 gpu나 cpu를 설정가능하다.
그밖에도 다양한 옵션이 있다.
결과물 확인
runs/train/에서 확인가능하다. best.pt에는 가장 좋은 결과가, last.pt에는 마지막 결과가 저장된다. beat.pt와 last.pt를 이용하여 이어서 학습도 가능하다고 한다.
우리 팀은 학습된 pt파일을 라즈베리파이에 옮겨 작동시켰다.
컴퓨터에서 확인하려면 다음과 같이 --source 에 이미지 경로를 작성해주면 된다.
python detect.py --source ./data/test_image.jpg
여기에서 마무리하도록 하겠다.
'학교 공부 > 졸업 프로젝트' 카테고리의 다른 글
| YOLOv5 학습 도중 겪은 시행착오 정리 (0) | 2023.05.21 |
|---|---|
| [Ubuntu20.04] Yolov5를 위한 우분투 세팅 (0) | 2023.05.16 |
| Cyberduck 설치 및 사용 (1) | 2022.11.25 |

